Overview
A critical part of SEO (and marketing!) is to never turn down an opportunity to have people stumble upon your products. You’re probably familiar with the bigger ones like the SEO snack pack and Google Posts, but there’s one that often doesn’t get enough attention: Google Knowledge Cards.
Wait, this thing?
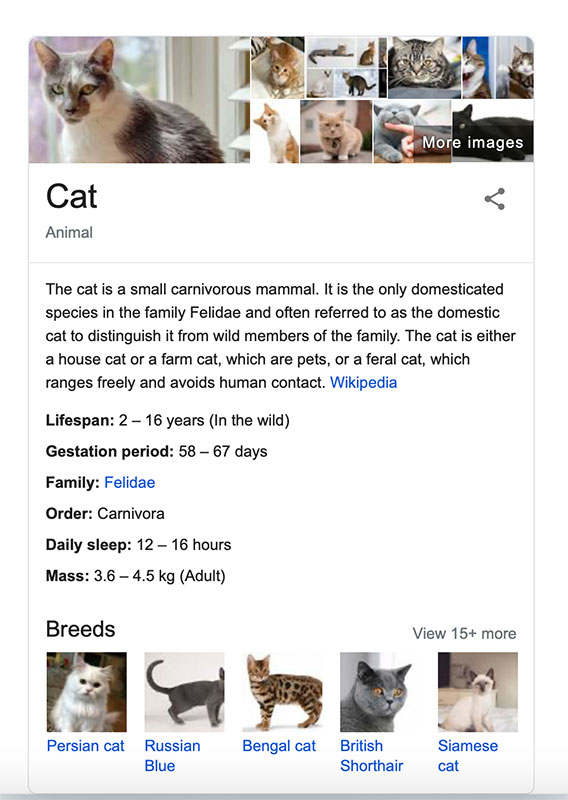
Yes, that thing exactly. Let’s see what happens when you click the largest image:
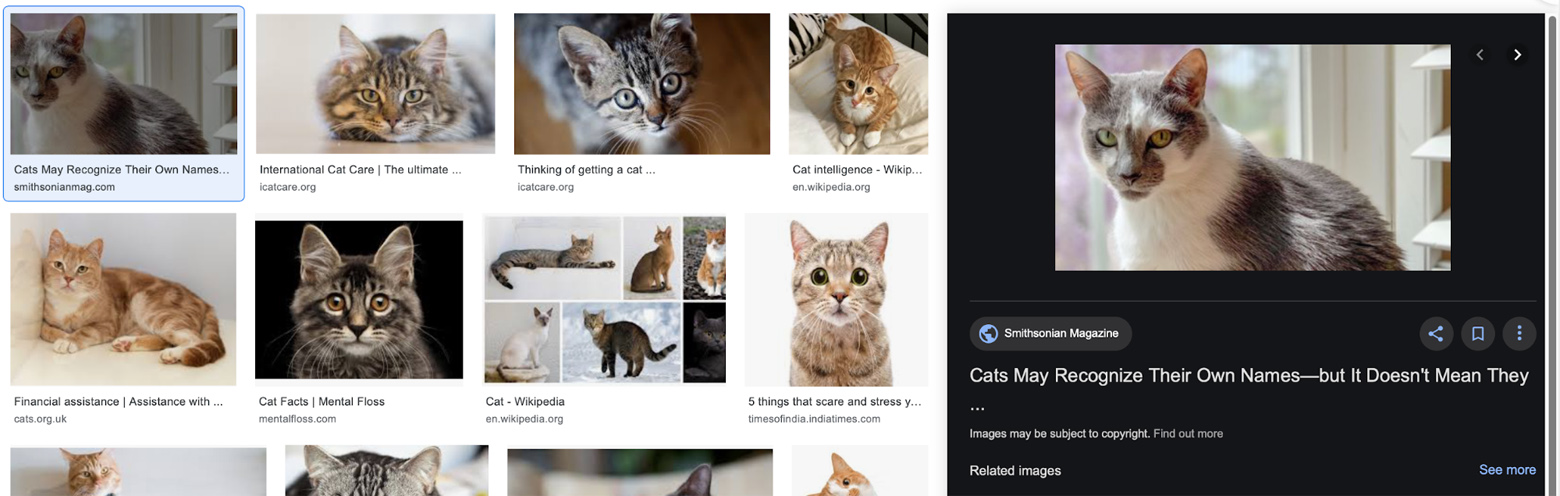
You go to Google Image Search, with the selected picture pre-opened and a clickable link to your content front and center.
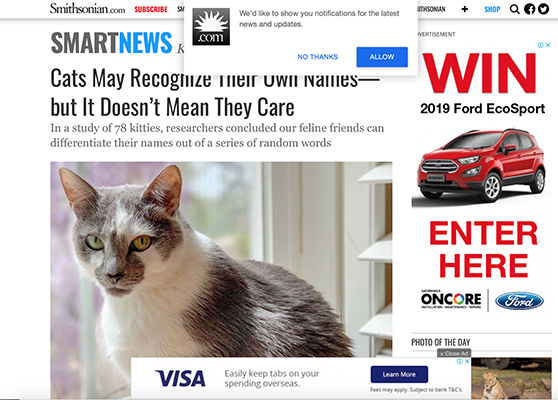
It’s another route that users can take from the SERP to your content, and one that SEO specialists critically underappreciate. Getting your image onto the knowledge card can be quite technical—it’s a mix of metadata management and image composition, and (like all SEO) is going to involve a bit of wearing down a mountain with a toothbrush. You can never guarantee you’ll get on the knowledge card, but you can take some simple steps to significantly increase your odds.
Often (but not always: see below), the knowledge card picks directly from Google Image Search and orders its pictures the same way: the main image is the first GIS result, then the top 4–8 next images appear in a collage beside it.
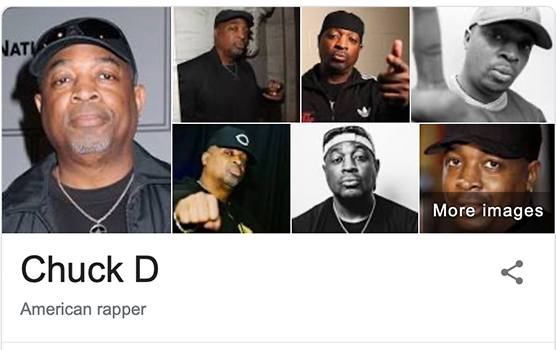
Though notably, some results only show the first image:
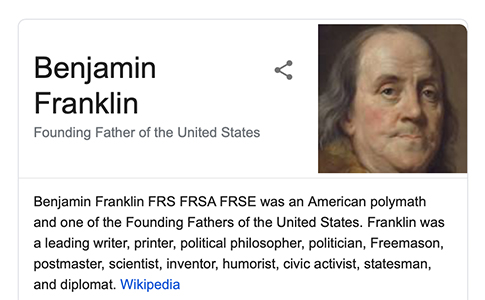
How that works under the hood is a closely-guarded Google secret, but I’ve noticed something that might explain it: they seem to choose based on image diversity. That is, if the top GIS results have more variety in terms of colour and composition, more images appear. Almost all of the results for Benjamin Franklin are based on the same two paintings, and the paintings are similar. It feels like Google might read that same-ness and decide to just show the one.

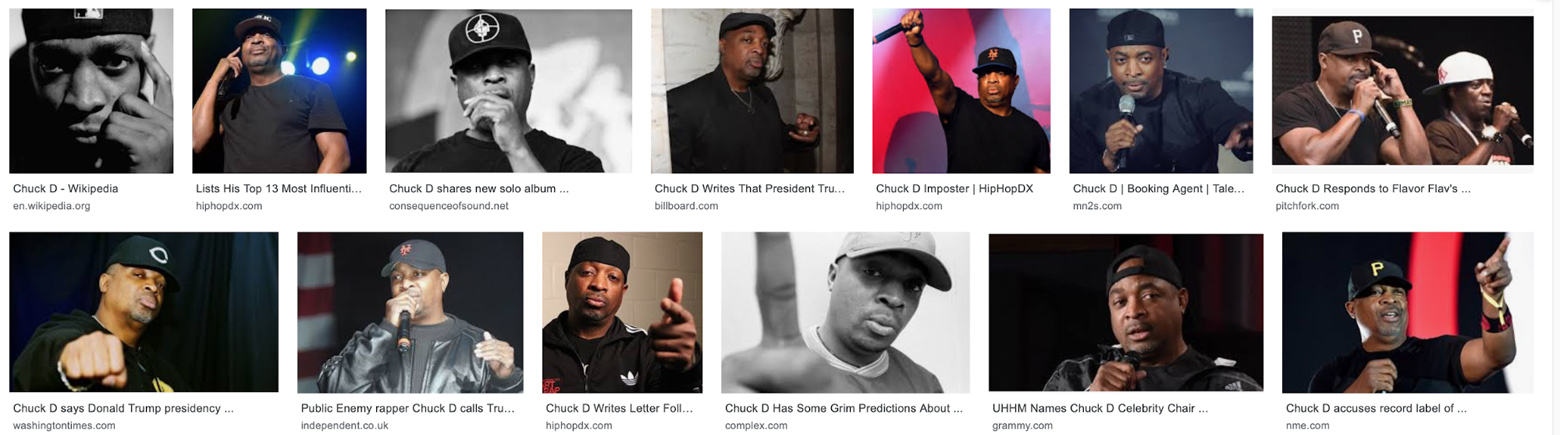
If you compare it to Chuck D, there’s a lot more different angles and compositions, and Google’s ML detection is going to see more variety.
It wasn’t like this on Knowledge Cards’ release in 2015: Franklin used to have a selection of, well … the same picture.

But here’s where it gets interesting: GIS and the Knowledge Cards both choose pictures based—at least partially—on the image’s link authority, but they’re not always the same. You might notice that the top GIS result for Chuck D doesn’t actually appear on the knowledge card. More speculation (based on testing and personal experience), but it might be looking for a more clear image of his face. Especially compared to GIS, Knowledge Cards don’t seem to like low-colour or low-contrast images.
The actual GIS search for ‘cat’ has the #1 knowledge card image at #8, and rearranges the results so it’s #1 if a user clicks from the card.

Machine learning algorithms tend to choose things based on how prototypical they are: how much cat-ness there is in a picture dictates how the algorithm chooses whether to put it on the card. The #1 GIS result has high contrast, but the cat’s body isn’t visible and that means it has less cat-ness than the #8 cat which was, well … more cat. When Google asks “is this a cat?”, it goes with the safer option.
When it asks “is this Chuck D?”, it looks at the first GIS result and sees that he’s very close to the camera (meaning less of him is visible), it’s black and white, and part of his face is obscured by shadow.

The card selects a medium shot with lighting that makes it more clear who you’re looking at.

Which could just be a coincidence, so let’s try it with somebody else:

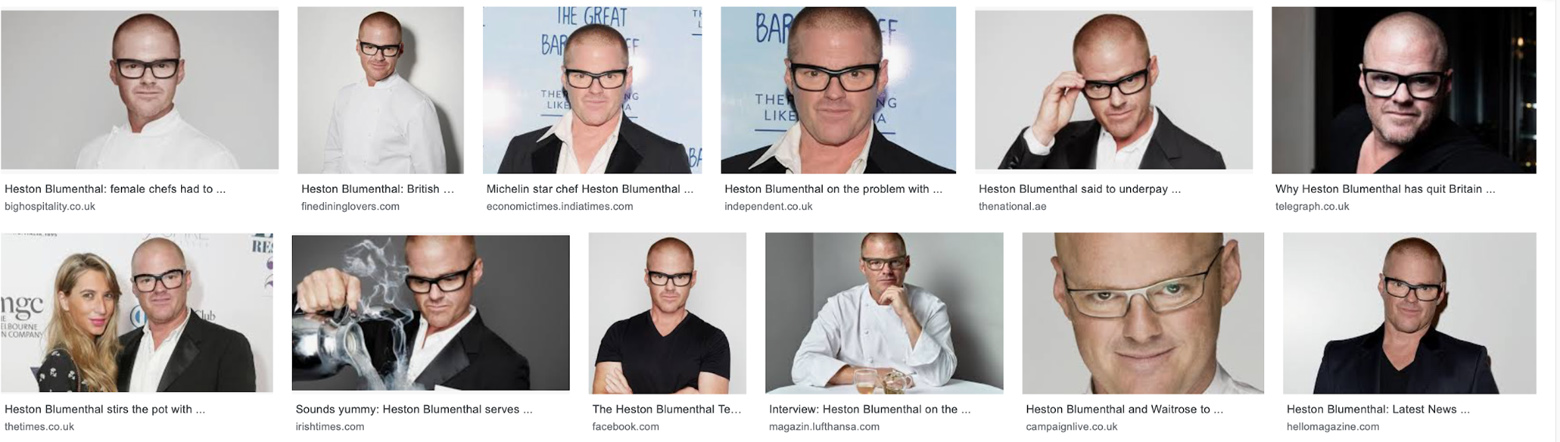
Now there’s something interesting: the picture with the yellow background isn’t even in the first 50 results, but it’s #1 on the Knowledge Card. In fact, the top GIS results and the knowledge card are extremely different—GIS has lots of white, but the card seems to be prioritizing black backgrounds and colour. Heston’s a pale guy who is often photographed in chef’s whites, so he blends in with lighter backgrounds. The knowledge card seems to prefer pictures of him in white on a black background, or in black on a white background. They also seem to like variety: the GIS results are a lot of him in chef’s whites on a white background, but the card has pulled more varied and colourful pictures up.
I don’t have any official confirmation that it’s using some sort of ML facial recognition algorithm, but everything about its behaviour points towards it, probably some internal version of the Google Vision AI. Which is a lot of words to say:
If your picture of a cat is more obviously a cat, it’s more likely to get selected for the knowledge card. Imagine you’re an AI trying to identify things, and seek out pictures that you’d have an easier time recognising. Or:
- High background contrast: the subject must be easily distinguished from their surroundings
- High definition: more detail makes it easier for the AI to figure out
- Lack of clutter: the more objects there are in the image, the harder it is for the algorithm to recognise
- Prototypical-ness: the subject must look as much like themselves as possible
- Distinction: the subject doesn’t look like anything or anyone else
Put those together, and—based on my testing, anecdotally verified by other SEO professionals I’ve been conferring with—you can significantly increase your chances of getting the plum position on the knowledge card.
The Other Half of the Equation
Even if you’ve got perfect image composition, I wouldn’t write off metadata management. I’m not sure the degree to which it influences primary knowledge card placement (see Heston) but it seems to increase your chances of appearing in the secondary knowledge card images, and is generally just good practice for SEO.
Right from the start, make sure your file name says what the image is. File names are the Google crawler’s first destination for figuring out what a picture is about. Changing imgnew0082021.jpg to Beige_Jacket_001.jpg is a tiny change that will give you a huge SEO boost and make your life easier in the office to boot.
With Google prioritising accessibility over the last few years, alt text has never been more important. Many people with vision impairment and other conditions need it to understand what they’re reading, and Google knows this and will give you a boost if you’re mindful of it. Like the filename, the Google spiders use alt text as a major context clue to work out the content of your image.
Also, image captions are critically important: they’re up there with titles and alt text, but many SEO managers leave them out entirely. They’re so simple to add, and they give critical context to your images that will help them to rise through the ranks. Make sure they’re actually attached to the images: if they’re not at least in the same <div> then the crawlers won’t be able to associate them with their parent image.
Finally, you want to make sure your structured image data is all in order. Google has fairly in-depth guidelines for developers here and it’s outside of the scope of this article to really go deep on it, but here’s the gist: the point of structured data is to be accurate. Don’t try to cram square pegs into round holes; your goal is to provide the crawlers with as much accurate information as possible, so they realise thatyour image deserves to be top of the pack.
So, In Closing
As you probably know, SEO is rarely a case of ONE NEAT TRICK: it’s more about tipping the odds in your favour by configuring things correctly. If you compose your images so they’re easier for the knowledge card ML to recognise and organise their metadata correctly and have an SEO strategy in place that means people are actually using your site, then you might just tip the balance in your favour and end up in a powerful (and underutilised) position on the SERP.
Good luck, and happy optimizing.

If you’re already and expert with this and you’re looking for SEO jobs in Kolkata, CodeClouds is always on the lookout for talented individuals like you!
How can we help?
Tell us about your inquiry and we’ll get back to you as soon as we can.








